- Published on
Branching Patterns for a growing team
- Authors

- Name
- Vinayak Ganapuram
- @vinayakkg
I had given a talk last month and there were a few interesting questions around the source code branching patterns that I had followed. Folks also wanted details on what were the other things I tried and how’s the current one working and if there are any challenges.
Any software development team today will have a source control repository and its used to store code written for the product/tech debts. There will also be steps to deploy the build and teams would have different repositories, at least one for each team e.g. Front End team, Backend team, QA team, DevOps team, etc. The development teams today follow most of the steps from Joel’s Test [list]. This list is a good indicator of the development team’s health and velocity.
When you have a smaller team and the product is getting started, the team generally ends doing trunk based development and there is only one default branch i.e. master. As the team starts growing and there is a demand for more features/hotfix/bug fixes, etc, various branching strategies based on the need get adopted. Source code branching is an important step and also a very involved one. Any miscommunication or misinformation around this can lead to a lot of issues that can hamper the development process and make the team inefficient. The entire team must definitely be on the same page on such initiatives.
Here, we will discuss the various branching strategies that I had used in the past to the current one that has helped me to scale and improve quality and drive efficiency.
Develop Based Development
In this mode of development, all developers work on only one branch for each repository. A branch under origin develop is in sync with master which developers use for development. Each developer develops and commits their work to this branch. This branch is the baseline for the entire team. The team has to keep synching/merging their locals to avoid any feature misses or delays in delivery. Once the feature/bug is code complete, feature/bug is tested once from the same branch (develop) and then it's merged to master for the final test/sanity and then deployed to production. One might say why test again? This could be part of the process to test twice and more so code cannot be committed to master while still in development. If you use master for testing you lose the ability to do hotfixes or other smaller ad-hoc releases. And you do that merge to master only after the 1st round of testing. Automation testing could reduce the time, yet, this is a 2 step process.
If you understood what I said above, you will also be able to relate to the problems with it.
With many developers working on various features required for the release, developers have to keep synching/pulling from the develop branch and if they happen to be working on the same file there would be a conflict and the developer has to resolve the conflict before one can proceed ahead with the work. More often developers discover conflicts only when they are about to push their changes to the branch at the origin. That is because git does not allow one to push if your local repository is not in sync with the branch, safety net - else the team will be in trouble.
You can set up commands/jobs that can auto sync local repositories but it could upset developers when they are in the middle of some change or they might turn it off to avoid accidental & surprising(unprepared) conflicts.
One more thing, this does not account for code reviews yet.
The entire setup would like this
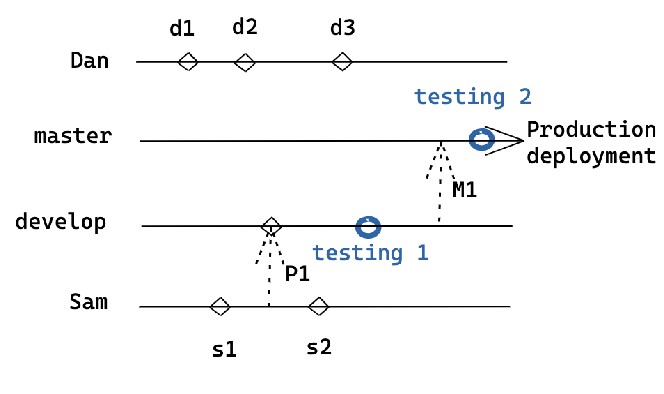
Let me explain what is happening here. Developers Dan and Sam are working on the project and have the branch develop as the baseline branch. Sam pushes a commit P1 to branch develop after thorough testing by him. This code has to now get synched by Dan to make sure there are no conflicts and is able to get the latest code worked on by Sam - it could be a small feature or API addition that Dan is waiting on from Sam. The longer we delay in merging, the larger could be the conflicts.
Pros
- No need to deal with many branches
- Suitable for small teams
- Easy to follow, understand and release
- Create one job in the build system for the release and you are good
Cons
- Loss of developer productivity resolving conflicts and synching often
- If the code is not modularized well, this can essentially slow the entire team
- Does not allow multiple pipelines (needed if working on many features) which can slow testing and delivery
- Cannot scale beyond small teams
Feature branch development
As the team size grows they may choose Feature branch strategy. In this mode of development, there are as many branches as there are features. And they are all created from master. The names of the branches resemble the features that get delivered as part of that work. e.g.flights-API, new-user-auth. This gives a lot of flexibility to the development teams and can prove very effective provided certain things are in check. There should not be any dependency between these features and their branches. If there are dependencies, then the team has to be cognizant of those and merge/sync at designated touch-points. Else, we are back to single branch development. In short, features need to be modular. The project manager/delivery manager needs to make sure there are no breakages/regression when these branches get merged with master for final delivery. Even if you have staggered features releases to deliver small chunks, you may miss features/bugfixes/hotfixes since there are frequent integrations. And that is only possible if you have a solid regression suite, great testing team, Self Testing Code and Automation Testing in place. Continuous Integration is also one of the ways to solve this. But lots of startups may not be able to put this in place or may not need for their scale. There is one more thing, merge conflicts. As the saying goes - if you fall off a tall building, the falling isn’t going to hurt you, but the landing will. Hence with source code: branching is easy, merging is harder.
The setup would like this
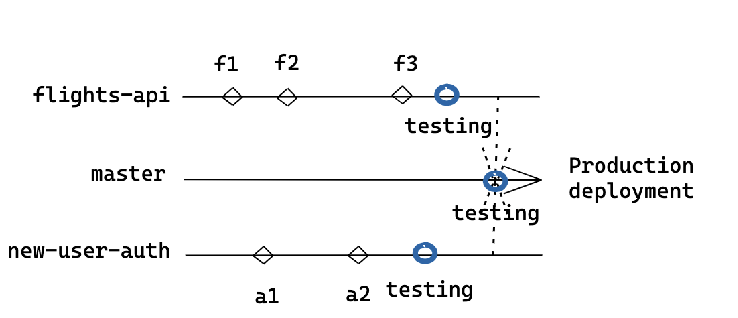
The above diagram is self exploratory. Also, each branch with many developers working would still have the same challenges as seen above in Develop Based Development
Pros
- Scales well
- Suitable for larger teams
- No more sync/conflicts with dependencies ironed out
- Ability to create pipelines
Cons
- Important to merge/sync with master as as possible. Larger merges can bring the system to a halt
- If the code is not modularized well, this can essentially slow the entire team
- Faster development can lead to code quality issues
- Can slow down if the right tooling and processes are not set in place
Variation of feature branch development
This one is very much similar to the previous one with few variations, essentially picking up the best parts and improving/building what is needed. Here we make sure the features are independent and if not then clearly laid out plan on sync so there are no gaps. Code modularity is also considered. New repositories may be created as you scale which also helps in breaking monoliths and lets you move forward faster. Deliver in smaller chunks as much as possible. Automate regression test suite, automate sanity test suite. Have good unit test coverage. Automate the entire build pipeline et al. And deploy from feature branches, not from the master. Yes, you heard that right! We will talk more below on the entire process.
There is one more important thing which helped a lot in scaling this and making sure we deliver quality and that is Code Review. I had adopted this religiously in my previous roles and hence I knew this could help. Even statistics say so.
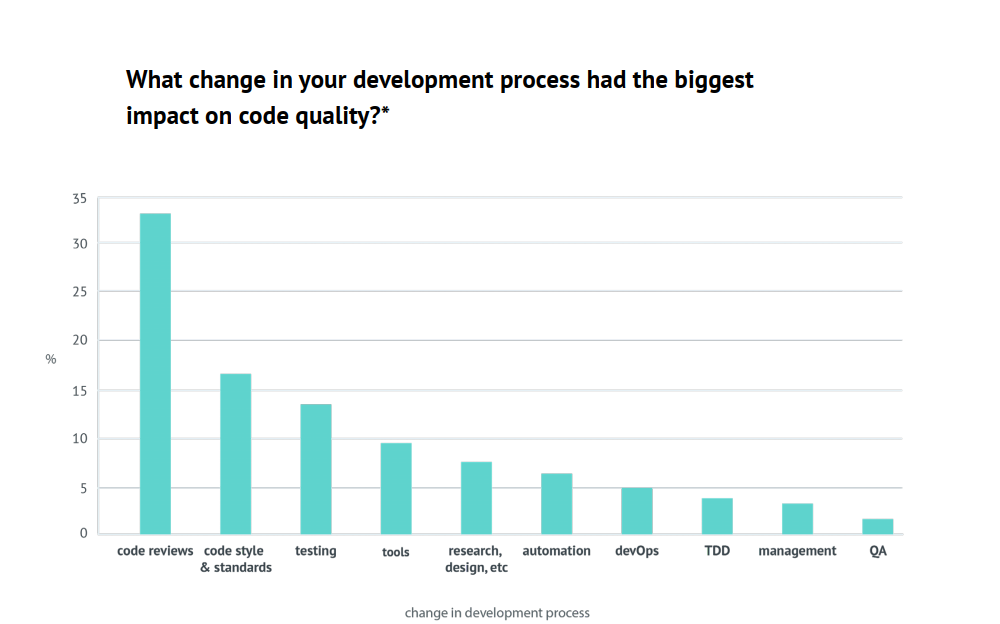
We follow an open source PR model using personal forks for code reviews and are working well. Everyone creates a PR to an origin branch from their fork and submits for review. The code review process is not the responsibility of a few leaders or architects. It's the collective responsibility of the team and everyone is an equal contributor. There is no elite class of people who own the rights to merge/quality. This way you can foster and drive quality across the board and each person feels equally responsible. Since you are trusting every member, people share a sense of pride and develop belongingness.
There is one more bit that has helped us maintain sanity in our approach and also avoid code misses or incomplete deliveries.
We have set up automation tasks that check for merge with master and if a certain branch is not in sync with master the build is rejected. This is done across all branches and in all environments. This has been a lifesaver. It forces developers to do frequent sync with master and avoids code misses and large merge issues.
The simple command that we use is as follows
git log --pretty="%H" | grep $(git rev-parse master)
If the above command does not produce any output, it means the code is not in sync and the build script is aborted
And to make sure our code is not missed and branches up for release have latest code, we raise a Auto PR to master using the below command
hub pull-request -m “Merge ${GITHUB_BRANCH_NAME} to master” -l “released-$currentDatetime”
In the future, we would like to run automation to create a report of branches not synched with master with their age. This will make sure we don’t have long lived branches that are out of sync.
The tweaked process looks like this
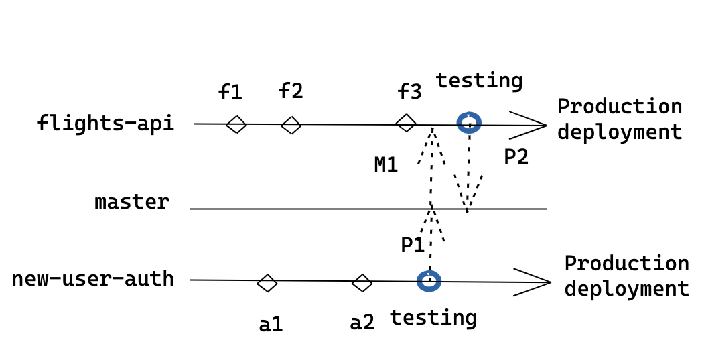
Let me quickly walk you through the process. Each feature branch gets deployed from the same branch post-testing. Then that branch is merged with master and other branches also take a reverse pull from the master. If not, the build scripts will catch for sure. :)
For completeness, the PR model is explained below
- Developers create branches on their forks
- Create a branch on central and raise a PR
- PR is reviewed and closed
- Code is tested
- Deployed to live
Pros
- Scales well
- Suitable for larger teams
- No more sync/conflicts with dependencies ironed out
- Ability to create pipelines
- Faster releases, auto PR/merges help
- No more code misses/feature misses
- With code review, quality is solved
Cons
- If the code is not modularized well, this can slow the entire team
- Requires fair bit of co-ordination (initially) so all understand the process
- Can be called an anti pattern.
Learnings
- Follow what works for you and your team
- Try and be ready to change if a strategy does not work
- Get management buy in for code-reviews so the timings are factored accordingly and there is enough visibility
- Make sure to showcase the value of code review and evangelize across the org. Use simple metrics like bugs reduced per build and post deployment.
- Encourage developers to run the code on their machines and review code
- Refrain from using reviewing code on browser, they are not native editors (long lines are still an issue)
- Keep your
mastersane and in release state - Its fine if a partially finished future goes live (backend done, Front end pending). Does not harm. Use feature flags where possible
Next steps
- Aim for high frequency integrations and make them friction free
- Automate as much as possible
- Follow continuous integration with good unit tests and integration tests
References
https://www.youtube.com/watch?v=Nffzkkdq7GM
https://martinfowler.com/articles/branching-patterns.html
https://www.codacy.com/ebooks/guide-to-code-reviews-II